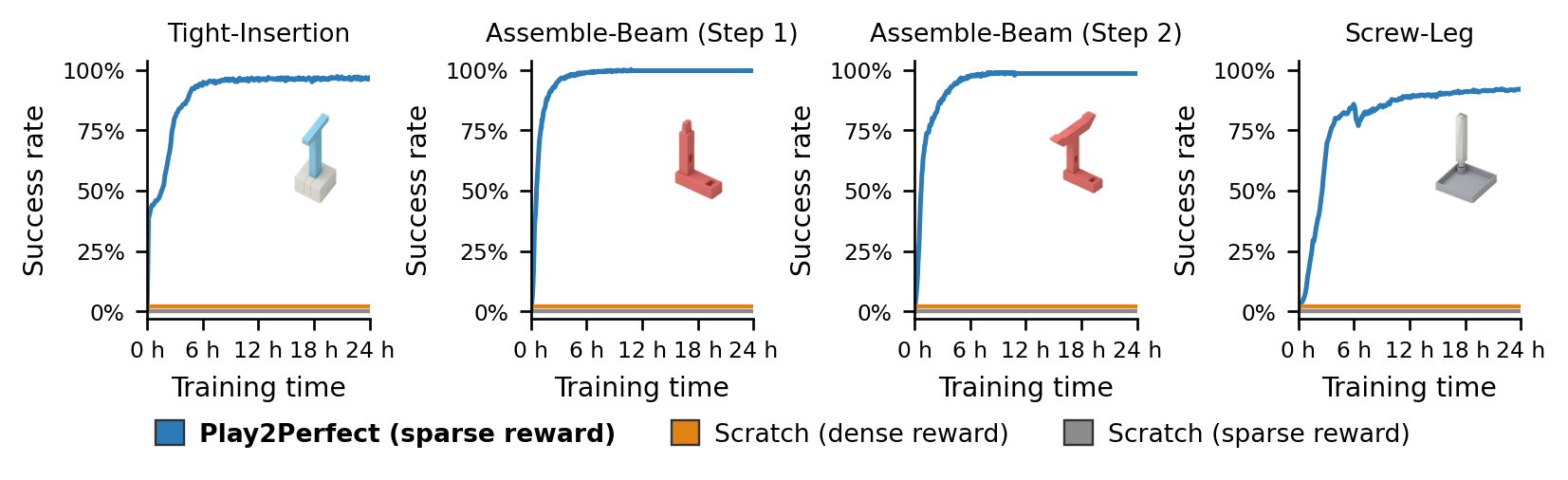
Play2Perfect Enables Rapid Learning of Assembly
Starting from a play-pretrained prior, Play2Perfect learns precise assembly with only sparse rewards—far faster than training from scratch, which stalls near zero even with the hand-crafted dense reward shaping we designed for it.